定义
绿色数据中心 机器学习 CPU能效 是本文核心解析的三个关键词。绿色数据中心是指通过节能技术、可再生能源利用和智能运维手段,最大限度降低能源消耗和环境影响的现代化数据中心设施。机器学习驱动的CPU能效优化与负载均衡是其中的核心技术方向——它利用AI模型实时分析CPU工作负载特征,动态调整处理器频率、电压和任务分配策略,在保证服务质量的前提下将单位算力的能耗降至最低。
绿色数据中心与机器学习技术的结合,核心目标之一是提升CPU能效,即用更少的电力完成同样的计算任务。根据 Uptime Institute 2025 年全球调查报告,电力成本已占典型数据中心运营支出的 55%-70%,其中 CPU 和内存子系统消耗了约 45% 的总电力。传统基于固定阈值或静态分区的节能策略,在面对波动的业务负载时往往效果有限,机器学习提供了一种能自适应、持续优化的替代路径。
工作原理
机器学习优化 CPU 能效的核心链路包含四个环节:数据采集、负载预测、决策执行和反馈闭环。
数据采集层
每台服务器通过 BMC(基板管理控制器)和操作系统接口,持续采集 CPU 利用率、每核心频率、内存带宽占用、缓存命中率、指令流水线停顿次数等数十个特征指标。现代 Intel Xeon Scalable 和 AMD EPYC 处理器内置的 RAPL(Running Average Power Limit)接口,可以直接读取每个 CPU 封装和内存子系统的实时功耗数据,精度达到毫瓦级。
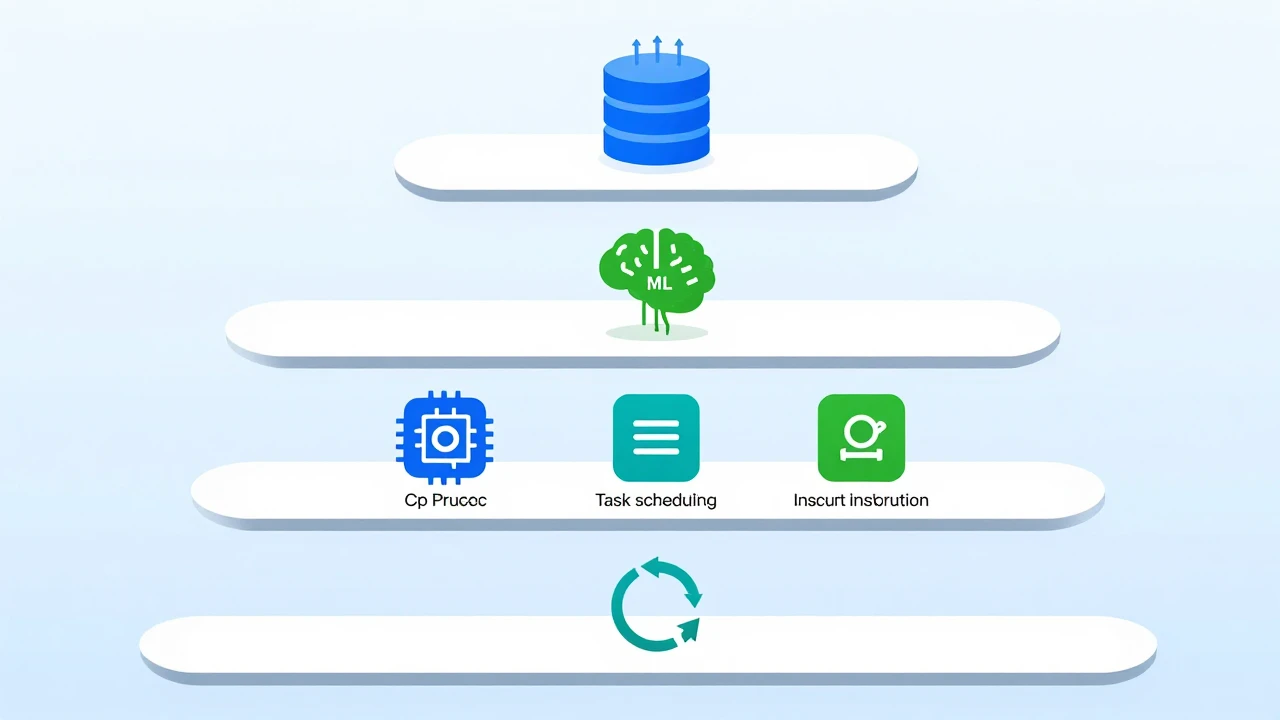
负载预测模型
采集到的时序数据输入到训练好的 ML 模型中。常用的模型包括:
– LSTM(长短期记忆网络):适合预测周期性负载模式,如电商促销期间的流量波形
– XGBoost / LightGBM:在特征维度较高时仍能保持毫秒级推理速度,适合在线预测场景
– Transformer 变体:Google 和 Meta 的实测数据显示,小型 Transformer 在 6-24 小时中长期负载预测上的 MAE(平均绝对误差)比 LSTM 低 12%-18%
模型输出的是未来 5 分钟到 2 小时内的各核心预期利用率和功率需求分布。
动态调频与任务调度
预测结果传递到两个执行模块:
CPU 频率与电压调节。 Linux 内核的 cpufreq 框架支持 ondemand、conservative、schedutil 等策略,但 ML 方案更进一步——不再是基于实时利用率做反应式调频,而是基于预测负载做前置调频。当模型判断未来 30 秒负载将上升 40% 时,系统提前提升频率和电压,避免突发请求积压;当预测负载将下降时,提前降低频率进入节能状态。Google 在 Borg 集群上的实验数据显示,这种预测式调频比 schedutil 策略节省 13%-22% 的 CPU 能耗。
任务与中断负载均衡。 传统 Linux 内核的 CFS(完全公平调度器)和 irqbalance 基于当前负载进行任务迁移。ML 增强的负载均衡器会结合历史负载模式和预测结果,提前将即将高负载的任务迁移到当前温度较低、频率余量更大的核心上,同时将中断处理程序绑定到最合适的核心,避免跨 NUMA 节点访问带来的延迟和额外能耗。关于 CPU 资源分配的基础概念,可参考 VPS和独立服务器的区别及适用场景详解(含 CPU 资源分配的基础介绍),以及 云计算与AI 分类中的调度优化文章。更多技术术语可查阅 托管百科词汇表。
反馈闭环
执行结果(实际功耗、温度、响应延迟)回传给模型进行在线学习。这使模型能持续适应硬件老化、负载偏移和环境温度变化,不需要周期性重新训练。
核心应用场景
超大规模云数据中心
AWS、Google Cloud 和 Microsoft Azure 已将 ML 驱动的 CPU 能效优化部署到数十万台服务器上。Google 公开的数据显示,其 TPU 和 CPU 集群通过 ML 负载预测与动态调频,每年减少约 300 兆瓦时的电力消耗,相当于一座中型风力发电机组的年发电量。
主机托管与独立服务器机房
中小型托管机房虽然规模不及云巨头,但单位电费占比更高。引入轻量级 ML 代理(资源占用约 200MB 内存、5% 单核 CPU)后,典型效果包括:
- 空闲时段 CPU 平均频率降低 35%,功耗下降 28%
- 突发负载响应时间保持在 10ms 以内,无感知降级
- 年度 PUE(电能使用效率)从 1.6 降至 1.45 以下
边缘计算节点
边缘节点空间和供电有限,散热条件差。ML 节能方案在这里的收益最明显——某 CDN 提供商在其 5000 个边缘节点上部署轻量 ML 模型后,节点 CPU 能耗降低了 31%,因过热触发的限频事件减少了 67%。

传统策略与 ML 方案的对比
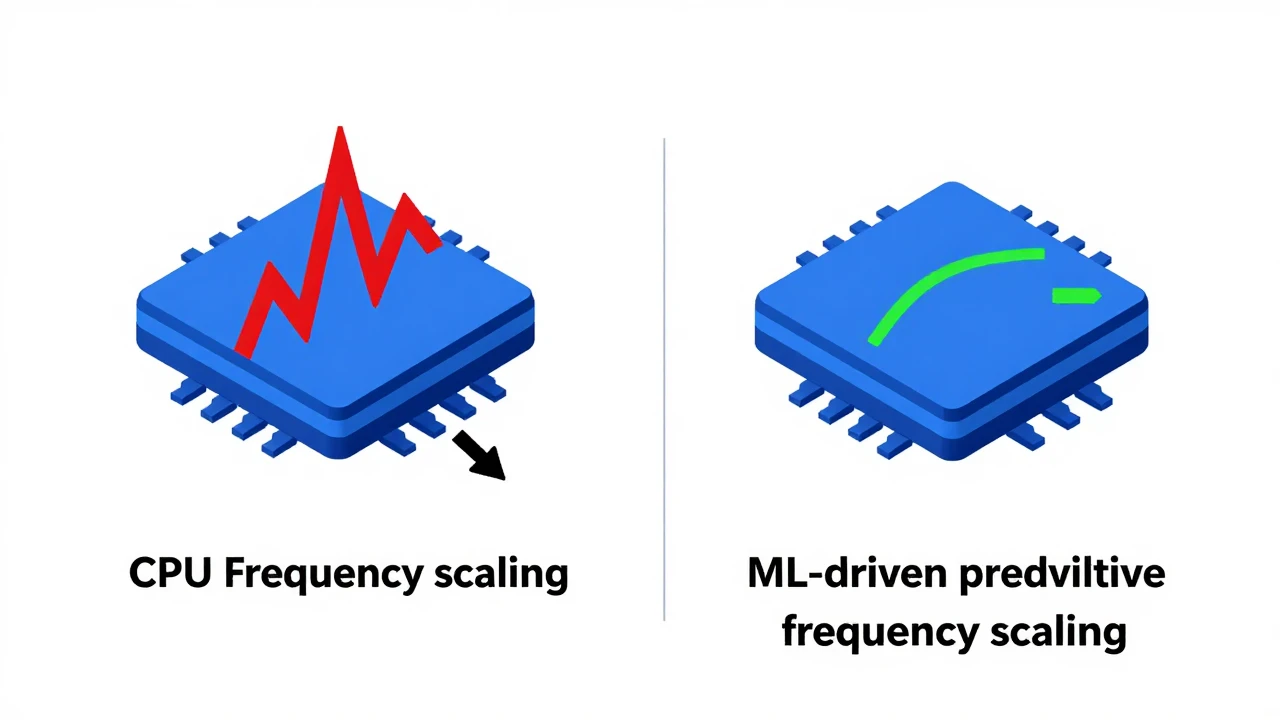
调频依据
- 传统策略:当前 CPU 利用率触发
- ML 增强策略:未来 5-120 分钟预测负载
响应方式
- 传统策略:被动跟随,利用率上升后才调频
- ML 增强策略:前置准备,提前调整频率
节能效果
- 传统策略:5%-10%
- ML 增强策略:13%-30%(取决于负载模式)
部署成本
- 传统策略:低,内核默认自带
- ML 增强策略:中,需额外 200MB-1GB 内存
适应性
- 传统策略:固定策略,无法适应负载变化
- ML 增强策略:在线学习,自适应硬件和环境变化
挑战与限制
模型泛化能力
在一个机群上训练的 ML 模型直接迁移到另一个硬件配置不同的机群时,能效优化效果可能下降 40%-60%。行业内通用的做法是使用迁移学习(Transfer Learning):基础模型在云端预训练,部署到各节点后仅需 1-2 天的本地数据微调即可达到接近最优的效果。
推理延迟开销
ML 模型的推理必须在毫秒级完成,否则会抵消节能收益。当前业界的经验阈值是推理耗时不超过 5ms。超过此阈值时,轻量级模型(如蒸馏后的 XGBoost 或 4 层小型 MLP)是更可靠的选择。
硬件支持要求
预测式调频和精细频率调节依赖现代 CPU 的硬件接口。Intel Sapphire Rapids 及更新架构、AMD Genoa 及更新架构支持更细粒度的每核心独立调频和 RAPL 功耗限制。2019 年以前的老旧处理器在这方面的能力有限,ML 优化的空间也相应缩小。
参考资料
- Uptime Institute. (2025). 全球数据中心调查报告 2025. https://uptimeinstitute.com/
- Google DeepMind. (2024). 机器学习在数据中心冷却与能效优化中的应用. https://deepmind.google/
- Intel Corporation. (2024). RAPL 接口规范——面向至强可扩展处理器. https://intel.com/
- 延伸阅读:云计算与AI 分类目录——了解AI基础设施相关词条
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏